| Druckversion: | | Nach dem Drucken: | | und zurück zum Dokument |
Sollte das Drucken mit diesem Schaltknopf nicht funktionieren, nutzen Sie bitte die Druckfunktion in Ihrem Browser: Menü Datei -> Drucken
Konzepte und Definitionen im Modul IV-6 Test der Regressions- und des Korrelationskoeffizienten
Vorbemerkungen
In diesem Abschnitt werden Verfahren diskutiert, mit denen von den empirischen Regressions- und Korrelationsergebnissen (bzw. im Exkurs auch von der Varianzanlyse) einer Stichprobe auf die entsprechenden Zusammenhänge in der Grundgesamtheit geschlossen werden kann.
Im Teil A basieren die Ergebnisse auf den einfachen Regressions- und Korrelationsmodellen, die auf der Plattform-Komponenten
"ViLeS 1"
im Modul
Einfach lineare Regressions- und Korrelationsanalysen entwickelt wurden.
Im Teil B werden die multiplen Regressions- und Korrelationsmodellen zugrunde gelegt, die auf der Plattform-Komponenten
"ViLeS 1"
im Modul
Multiple Regressions- und Korrelationsmodelle vorgestellt wurden.
Im Teil C (Exkurs) werden die Testansätze zur zweifaktoriellens Varianzanalyse skizziert, die auf der Plattform-Komponenten
"ViLeS 1"
im Modul
mehrfaktorielle Variananalyse
präsentiert wurde.
Teil A: Test der einfachen Regressions-und Korrelationskoeffizienten
1. Die Regressions- und Korrelationsmodelle in der Stichprobe und in der Grundgesamtheit
a) Die Regressionsmodelle
Die in einer Stichprobe realisierte Regressionsfunktion entstammt dem Universum aller möglichen unterschiedlichen Regressionsfunktionen, wie sie in der folgenden Abb. skizziert werden:
Abb. IV-21: Stichproben im Regressionsmodell

Der Hypothesentest im Regressions- und Korrelationsmodell konfrontiert eine Hypothese über die Regressionsfunktion der Grundgesamt mit der Regressionsfunktion einer Stichprobe:
X1ic = A + B · X2i ⇔ x1ic = a + b · x2i
Mit der Ausweitung des Modells der linearen Einfachregression (vgl. ViLeS 1, Kap. 12) erfolgte eine Umbenennung des Variablenpaars (y , x) in ( x1, x2). Zur Unterscheidung der Funktionen werden ausserdem die Variablen und Parameter der Funktion der GG mit Großbuchstaben gekennzeichnet.
Das Regressionsmodell der Grundgesamtheit lässt sich nun wie folgt komplettieren:
X1i = A + B · X2i + Ui
b) Die Korrelationsmodelle
Der Determinationskoeffizient der Stichprobe ergab sich in ViLeS 1 als Verhältnis der erklärten Abweichung zur Gesamtabweichung:
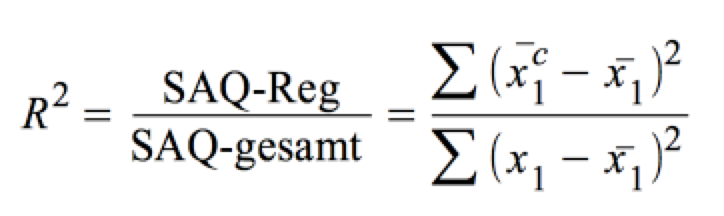 .
.
Der Determinationskoeffizient der Grundgesamtheit lässt sich nun entsprechend formulieren:
 .
.
c) Die Testansätze
Für das Regressions- und Korrelationsmodell ergeben sich daraus drei Testansätze:
ein Hypothesentest für die Regressionskonstante A
ein Hypothesentest für den Regressionskoeffizienten B und
-
ein Hypothesentest für den Korrelations- bzw. Determinationskoeffizienten.
2. Der Test des Regressionskoeffizienten B
Wir betrachten zuerst das Testmodell für B, da sich darüber auch eine Aussage zur generellen Existenz eines Zusammenhang ableiten lässt.
a) Die Stichprobenverteilung der b
Die Stichprobenverteilung der b, wie sie in Abb. IV-2 dargestellt ist, lässt sich unter der Bedingung einer normalverteilten Grundgesamtheit aus den Annahmen über den Regressionskoeffizienten der Grundgesamtheit und die Fehlerverteilung der Ui in der Grundgesamtheit bestimmen.
Abb. IV-22 Stichprobenverteilung der b
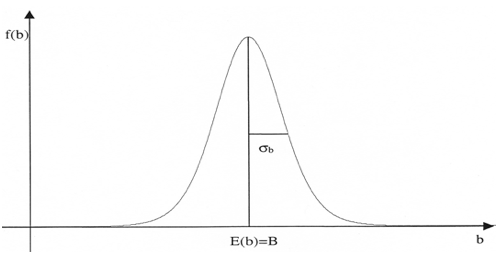
b ist normalverteilt mit einem
Erwartungswert E(b) = B und einer
Standardabweichung σb :
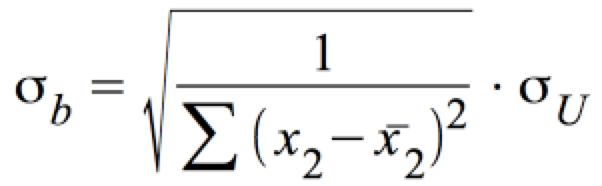 .
.
σU lässt sich über die Standardabweichung der Fehler ŝu schätzen:
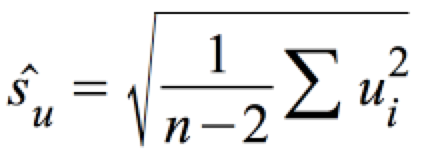 .
.
b) Das Testkonzept
Getestet wird die Hypothese:
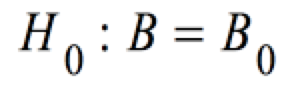
Der Test wird auf der der Basis einer t-Verteilung durchgeführt.
tb ist t-verteilt bei φ = n-2 Freiheitsgraden:
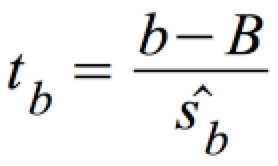
mit:
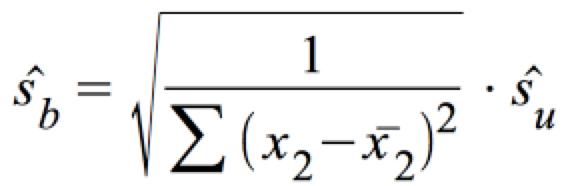 .
.
Für n ≥ 30 kann diese t-Verteilung durch eine Standardnormalverteilung approximiert werden mit:
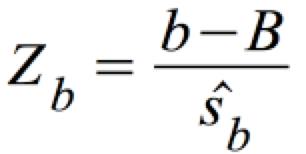
c) Der Annahme- und Ablehnungsbereich
Für die Hypothese
können bei n ≥ 30 folgende Grenzen für die Annahme- und Ablehnungsbereiche definiert werden:
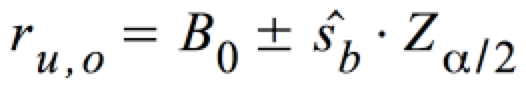
Diese können wie folgt graphisch dargestellt werden:
Abb. IV-23: Annahme- und Ablehnungsbereiche für b
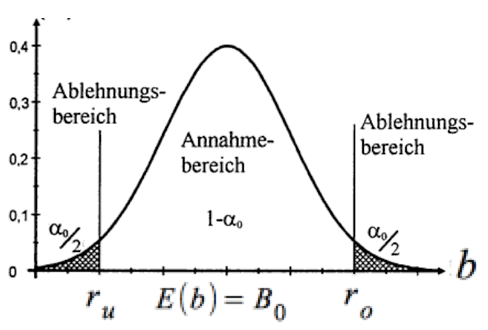
Üblicherweise wird vor allem die Hypothese getestet:
 ,
,
mit:
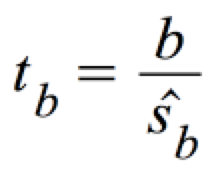
Dies beinhaltet implizit die Prüfung, ob überhaupt ein Zusammenhang zwischen den Variablen besteht.
Bei positiven Werten von b ergeben sich auf der Basis der t-Verteilung für die Hypothese folgende Annahme- und Ablehnungsbereiche:
Abb. IV-24: Die Grenze des Annahmebereichs
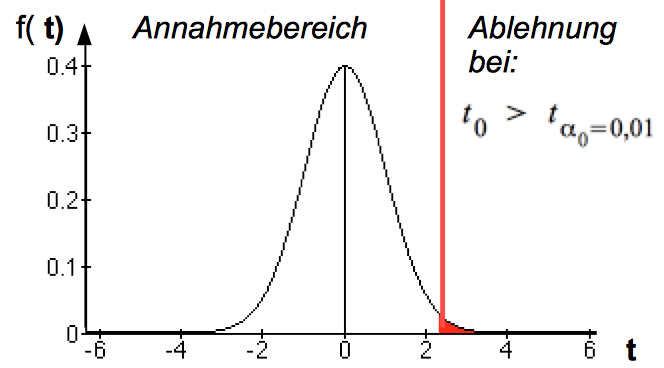
tα0 ergibt sich bei φ = n - 2 Freiheitsgraden und einem Signifikanzniveau von α0 aus der Tabelle oder einem Rechner.
Alternativ kann die Nullhypothese zurückgewiesen werden, wenn die für t0 berechnete Signifikanz von α < 0,01 bzw. < 0,05 ist.
Bei negativen Werten von b ergibt sich der Ablehnungsbereich für die Hypothese mit t < -tα0 .
3. Der Test der Regressionskonstanten A
a) Die Stichprobenverteilung der a
Die Stichprobenverteilung der a lässt sich unter der Bedingung einer normalverteilten Grundgesamtheit aus den Annahmen über die Regressionskonstante der Grundgesamtheit und die Fehlerverteilung der Ui bestimmen.
a ist normalverteilt mit einem
Erwartungswert E(a) = A und einer
Standardabweichung σa :
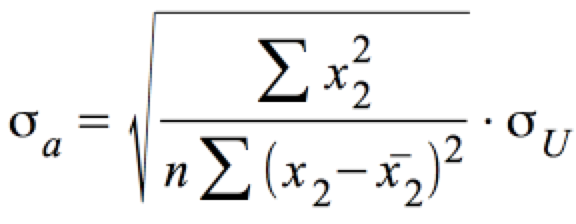 .
.
σU lässt sich wieder über die Standardabweichung der Fehler ŝu schätzen:
.
b) Das Testkonzept
Getestet wird die Hypothese:
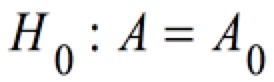
Der Test wird auf der der Basis einer t-Verteilung durchgeführt.
ta ist t-verteilt bei φ = n-2 Freiheitsgraden:
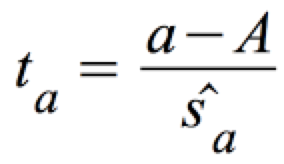
mit:
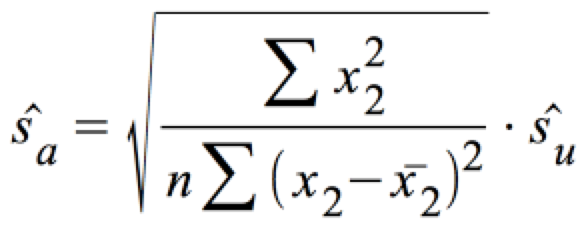 .
.
Für n ≥ 30 kann diese t-Verteilung wieder durch eine Standardnormalverteilung approximiert werden mit:
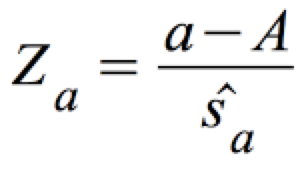
c) Der Annahme- und Ablehnungsbereich
Für die Hypothese
können bei n ≥ 30 folgende Grenzen für die Annahme- und Ablehnungsbereiche definiert werden:
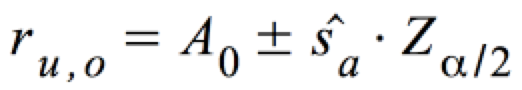
Diese können wie folgt graphisch dargestellt werden:
Abb. IV-25: Annahme- und Ablehnungsbereiche für a
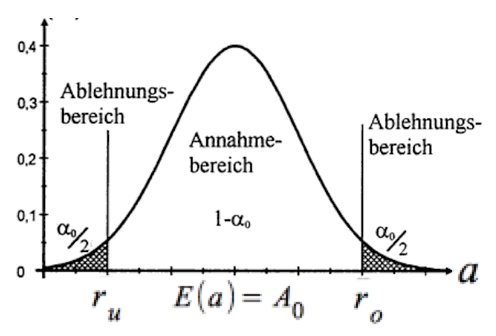
Üblicherweise wird auch hier die Hypothese getestet:
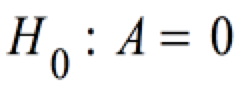
mit:
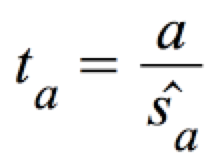 .
.
Für die Null-Hypothese ergeben sich die Annahme- und Ablehnungsbereiche auf der Basis der t-Verteilung wie in Abb. IV-24 dargestellt.
4. Der Test des Determinationskoeffizienten
ρ 2 = 0
a) Die Ausgangsbedingungen des Tests
Der Test für die Stärke des Zusammenhangs zwischen den beiden Variablen X1i und X2i kann sich nicht unmittelbar auf eine Verteilung der R bzw. der R2 stützen.
Sowohl die Gesamtvarianz der Stichprobe S12, wie die Fehler-Varianz der Stichprobe Su2 , stellen keine erwartungstreuen Schätzer für die entsprechenden Varianzen der Grundgesamtheit dar.
-
Aus diesem Grund sind auch R bzw. R2 keine erwartungstreuen Schätzer für die entsprechenden Größen der Grundgesamtheit. Vielmehr überschätzen die Koeffizienten der Stichprobe in der Regel die der Grundgesamtheit.
-
Ein erwartungstreuer Schätzer für ρ 2 ist der korrigierte Determinationskoeffizient :
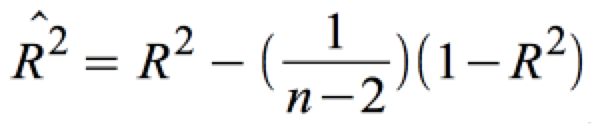 .
.
b) Die Stichprobenverteilung der Testgröße F
Die Stärke des Zusammenhangs wird durch ein Verhältnis von Varianzen bzw. Summen von Abstandsquadraten ermittelt.
Die Stichprobenverteilung der Testgröße basiert ebenfalls auf Summen von Abstandsquadraten, setzt jedoch die erklärte SAQ (SAQ-Reg) ins Verhältnis zur unerklärten Summen der Abstandsquadrate (SAQ-Res):
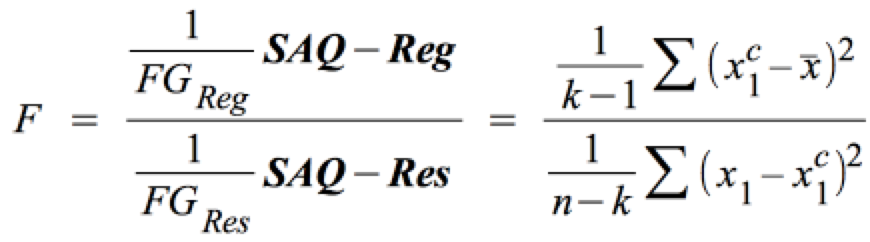 .
.
Die Größe F folgt einer sog. F-Verteilung, die als Verhältnis zweier χ 2-Verteilungen unter Berücksichtigung der entsprechenden Freiheitsgrade FG-Reg = k -1 und FG-Res = n - k definiert ist, weshalb man präziser schreibt:
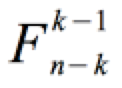
Aufgrund der quadratischen Ausgangswerte nimmt F nur positive Werte an und ähnelt in ihrer Form der Chi-Quadrat-Verteilung:
Abb. IV-26: F-Verteilung
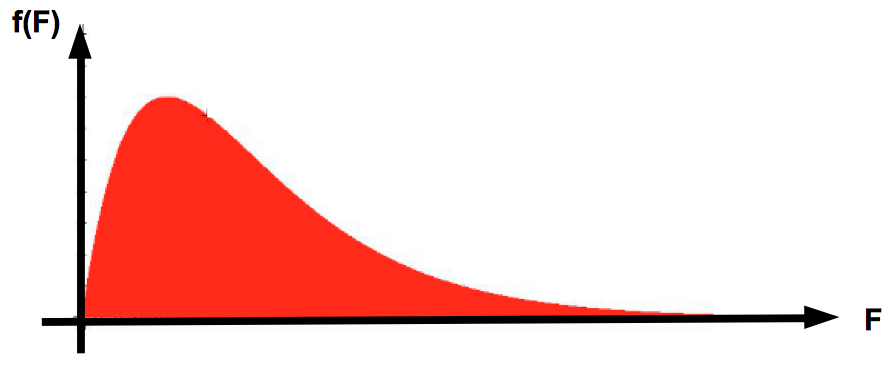
Im Falle einer einfachen Regressions-/Korrelationsanalyse mit k = 2 Variablen, weist die Regression einen Freiheitsgrad von Eins auf: FG-Reg = 2 - 1 = 1.
Für diesen Fall ist die F-Verteilung durch eine t-Verteilung darstellbar mit:
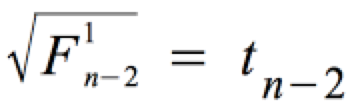
c) Der Annahme- und Ablehnungsbereich
Für die Hypothese ρ = 0 können bei einem Signifikanzniveau von α = 0,05 folgende Bedingungen für die Annahme- bzw. Ablehnung definiert werden:
Abb. IV-27: Annahme- und Ablehnungsbereiche für F
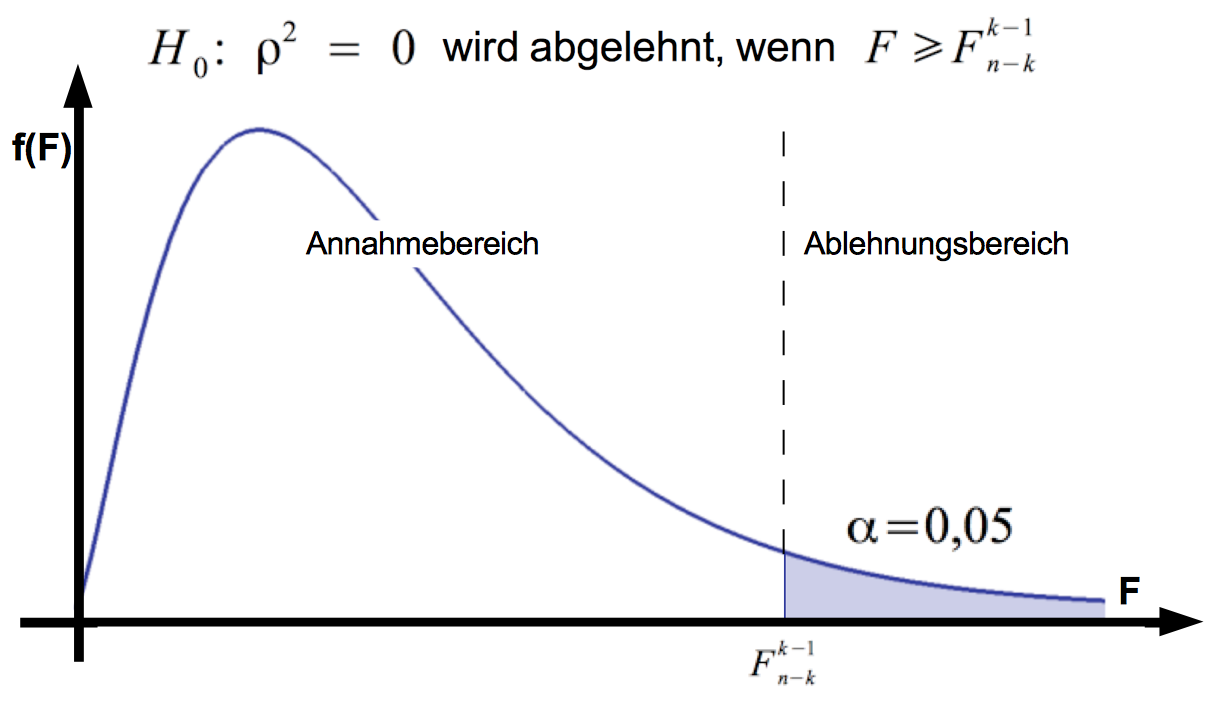
Über diesen externen Link finden Sie zur Abb. IV-27 den F-Verteilungsplotter von N. Johnston , mit dem Sie die F-Verteilung für beliebige Freiheitsgrade darstellen können.
5. Exkurs: Der Test des Korrelations- bzw. des Determinationskoeffizienten bei
ρ2 ≠ 0
Für ρ ≠ 0 erlaubt die sog. Fisher's Z-Transformation einen Test beliebiger, von ρ = 0 abweichender Hypothesen.
Für n ≥ 50 ist Z r normalverteilt mit:
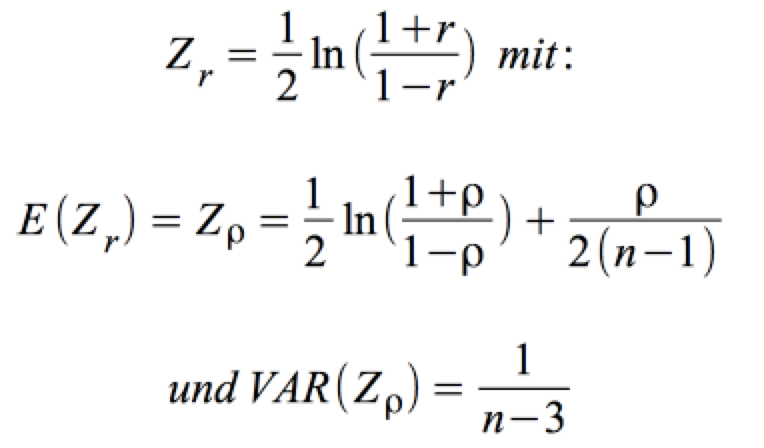
Daraus ergibt sich eine Standardnormalverteilung mit Z:
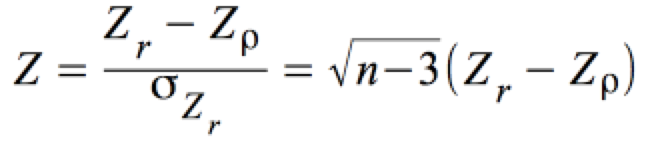 ,
,
aus der folgende Annahme- und Ablehnungsbereiche resultieren:
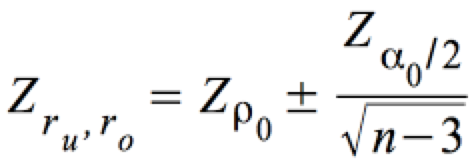
Über diesen Link finden Sie eine eine Umrechnungstabelle r --> Zr .
Hinweise:
Der Arbeitschritt "Beispiele und Aufgaben" zum Test des linearen Regressions- und Korrelationsmodells findet sich
hier
Teil B dieses Moduls "Test der multiplen Regressions- und Korrelationsmodelle" findet sich unter dem Link "Nächster Arbeitsschritt" in der Fußleiste.
letzte Änderung am 5.4.2019 um 4:24 Uhr.
Adresse dieser Seite (evtl. in mehrere Zeilen zerteilt)
http://viles.uni-oldenburg.de/navtest/viles2/kapitel03_Hypothesentests/modul04_Test~~lder~~lRegression-~~lund~~lKorrelationskoeffizienten/ebene01_Konzepte~~lund
~~lDefinitionen/03__04__01__01.php3