|
VII Der statistische Vergleich
- Einleitung und Modulübersicht -
1. Die Funktion des statistischen Vergleichs
Das Ziel dieses eher anwendungsorientierten Kapitels ist es einerseits die bisherigen eindimensionalen statistischen Methoden - im Sinne einer komplexeren Betrachtung der in den Daten enthaltenen Informationen - nochmals praktisch aufeinander zu beziehen, gleichzeitig aber über den eindimensionalen Rahmen hinauszugehen.
Das Kapitel stellt somit das Bindeglied zwischen einer eindimensionalen und einer mehrdimensionalen (hier vorerst zweidimensionalen) statistischen Analyse dar.
a) Die Grenzen eindimensionaler Analysen
Ausgangspunkt der statistischen Analyse ist eine numerische Größe. Eine Zahl von "2000" besagt erst einmal nichts.
Wenn zusätzlich bekannt ist, dass damit ein Einkommensbetrag in EUR gemeint ist, hat man zumindest eine Aussage über einen realen Sachverhalt. Damit eine Zahl also zum Element eines Datensatzes wird, bedarf es der sog. Metadaten.
Ob allerdings 2000 EUR ein niedriges, mittleres oder hohes Einkommen bedeutet, ergibt sich erst aus der Kenntnis der Einkommensverteilung. Aus der Relation des einzelnen Datums zur Gesamtheit der Daten wird dieser Zahlenwert zu einer Information über den finanziellen Status einer Person.
Die faktische, soziale und ökonomische Bedeutung dieser Information erschließt sich durch einen Vergleich, entweder in zeitlicher oder in regionaler Hinsicht. Erst aus dem Verhältnis einer eindimensionalen Verteilungen zu einer anderen resultiert ein Verständnis deren struktureller Relevanz. Mit anderen Worten: Um Strukturen zu vestehen, muss man sie aufeinander beziehen.
Um darüber hinaus die Prinzipien zu verstehen, nach denen soziale oder ökonomische Systeme funktionieren, ist es notwendig, Strukturen gedanklich zu verknüpfen. In analytischer Hinsicht sind dazu multidimensionale statistische Methoden einzusetzen.
b) Die Stufen des statistischen Erkenntnisprozesses
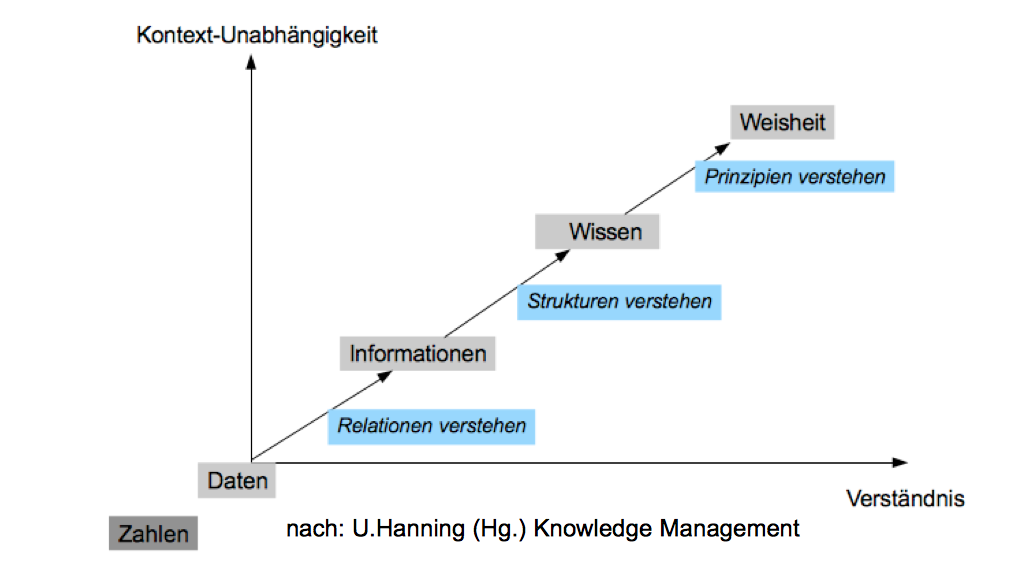
Der Erkenntnisgewinn geht in diesem Prozess zunehmender methodischer Komplexität, wie in Abb. 7-1 dargestellt, einher mit zunehmender Kontext-Unabhängigkeit der statistischen Information. Ob der Prozess schlussendlich zur "Weisheit" führt, mag dahingestellt bleiben.
Abbildung 7-1: Der statistische Erkenntnisprozess
2. Die Formen des statistischen Vergleichs
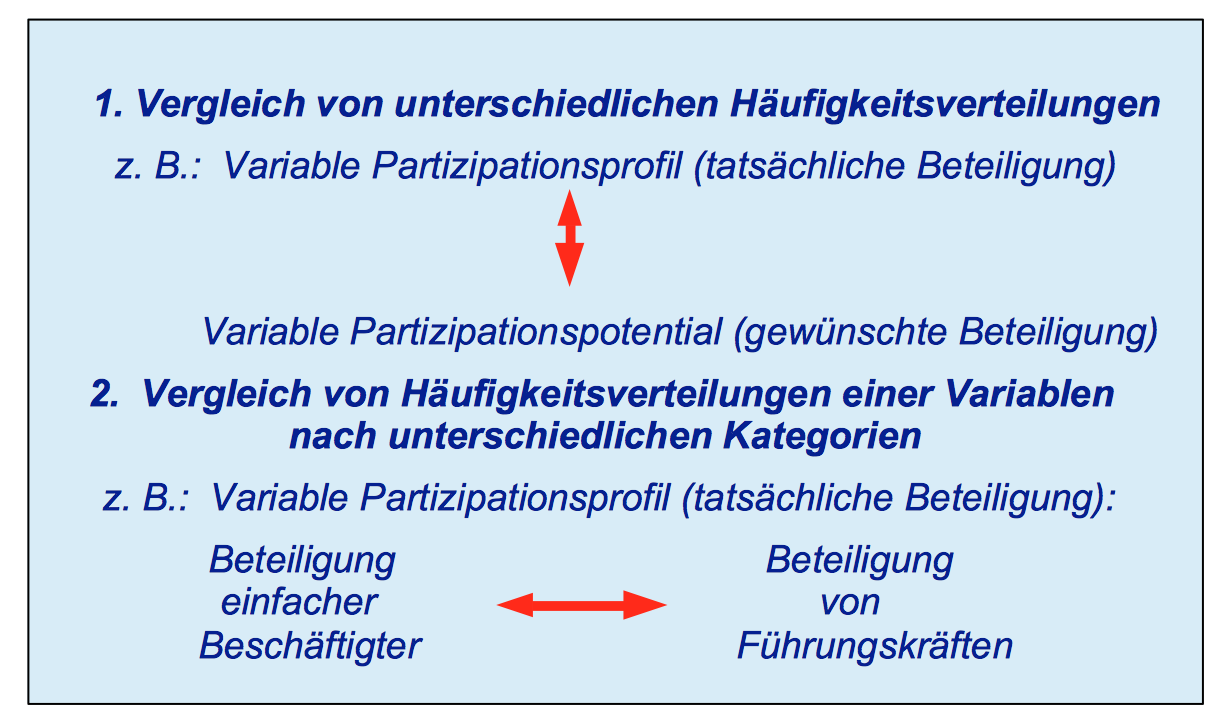
Die Gegenüberstellung von Verteilungen macht dann Sinn, wenn es zwischen beiden Sachverhalten eine formale oder eine sachlogische Beziehung gibt.
Eine formale Beziehung ist dann gegeben, wenn die beiden Datenreihen Gleiches oder Ähnliches in verschiedenen räumlichen oder zeitlichen Kontexten beschreiben, z.B. Einkommensverteilungen für verschieden Jahre oder für verschiedene Länder einander gegenüberstehen.
Ein zweiter Anlass könnte ein sachlicher Bezug zwischen den Daten sein, z.B. der zwischen einer Verteilung des Bruttoeinkommens und der des Nettoeinkommens oder im Beispielsdatensatz der zwischen der Verteilung der tatsächlichen Beteiligung und der gewünschten Beteiligung an betrieblichen Entscheidungen.
In den genannten Fällen ist die Vergleichbasis eine gemeinsame Skala der Messung.
-
Ein sachlogische Verknüpfung der beiden Verteilungen liegt dann vor, wenn die Ausprägungen einer Variablen von einer anderen Variablen kausal beeinflusst werden, wenn also z.B. die tatsächlichen Entscheidungskompetenzen vom Bildungsabschluss oder dem betrieblichen Status der Beschäftigten abhängen. In diesen Fällen bietet es sich an, den Datensatz nach den Kategorien aufzuteilen und die kategorial unterschiedenen Verteilungen mit einander zu vergleichen.
Abbildung 7-2: Vergleichsmöglichkeiten und Beispiele
3. Der Schritt zur Analyse statistischer Zusammenhänge
Mit der Betrachtung einer Verteilungen nach unterschiedlichen Kategorien, wie im Beispiel der Analyse gruppenspezifischer Unterschiede in der Beteiligung an den betrieblichen Entscheidungsprozessen, bereiten wir die Analyse der Zusammenhänge zwischen zwei Variablen vor.
Dieses Thema wird in den nächsten vier Kapiteln in tabellarischer und graphischer Form und mit den entsprechenden Maßzahlen bearbeitet, wobei wir sehen werden, dass auch hier das Skalenniveau der Daten die Konzeption der Modelle wesentlich bestimmt.
Wählen Sie ein Modul: - VII-1 Der Vergleich unterschiedlicher Variablen
- VII-2 Der Vergleich von Kategorien einer Variablen
|