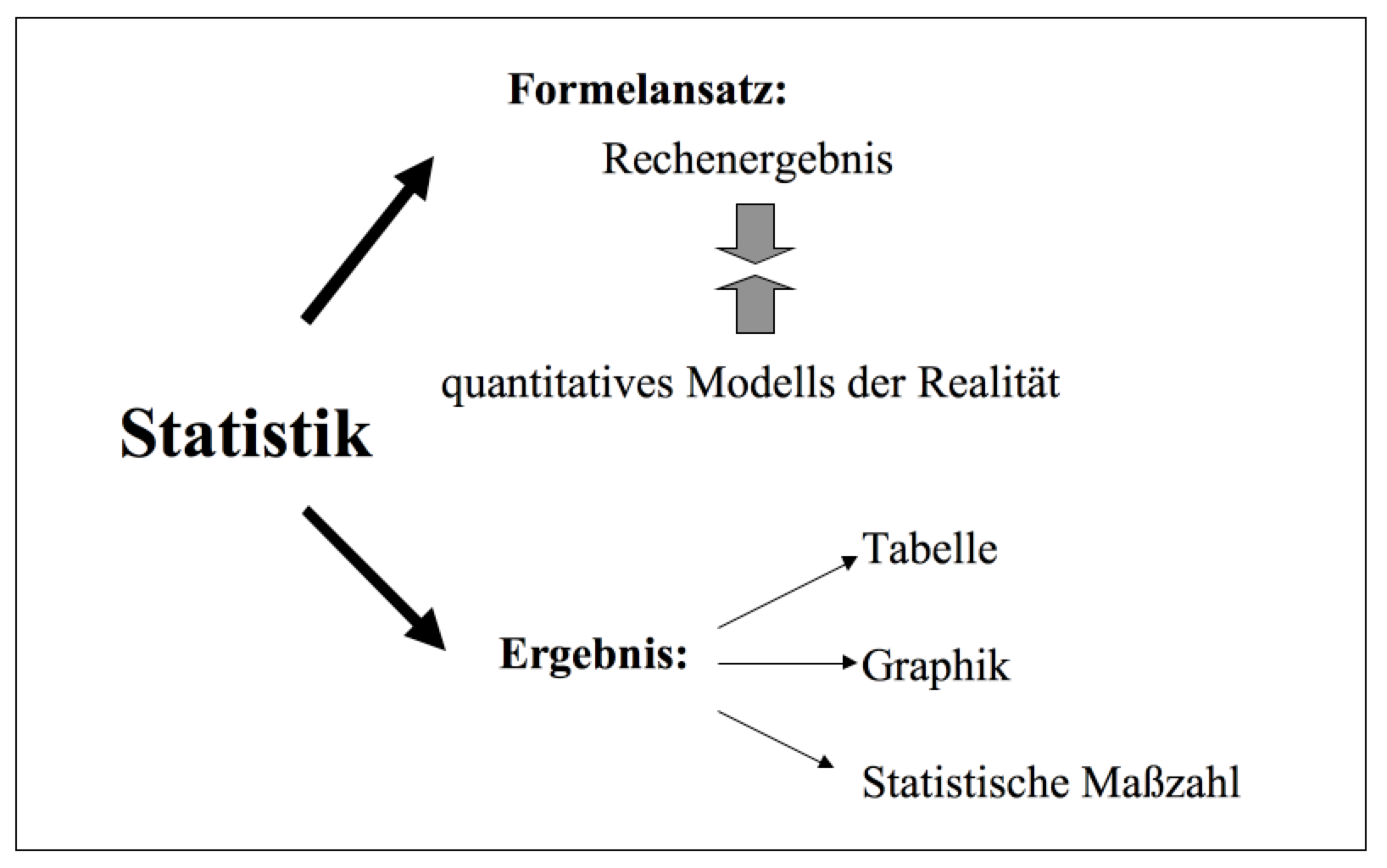
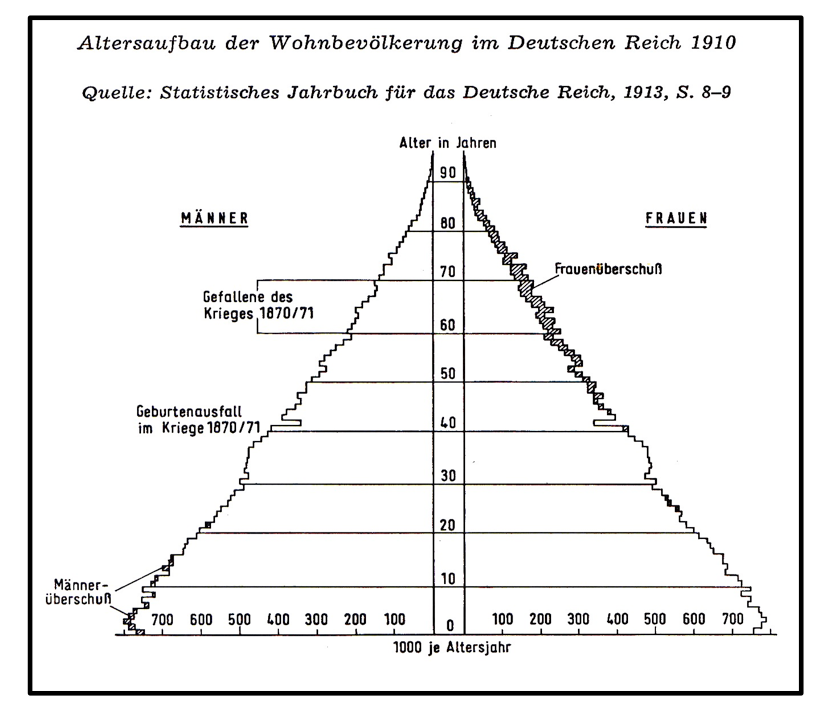
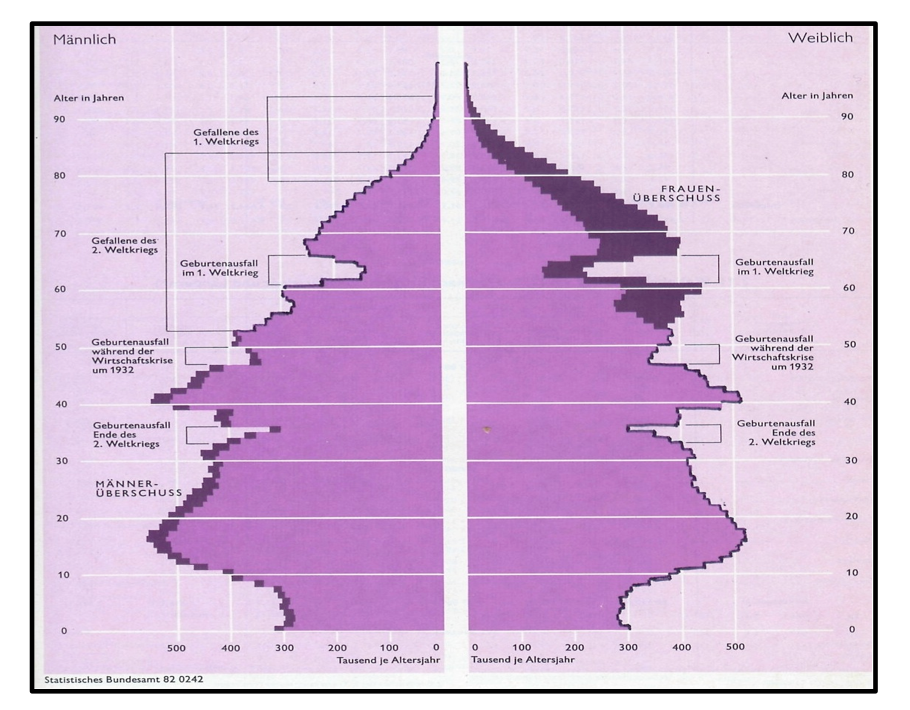
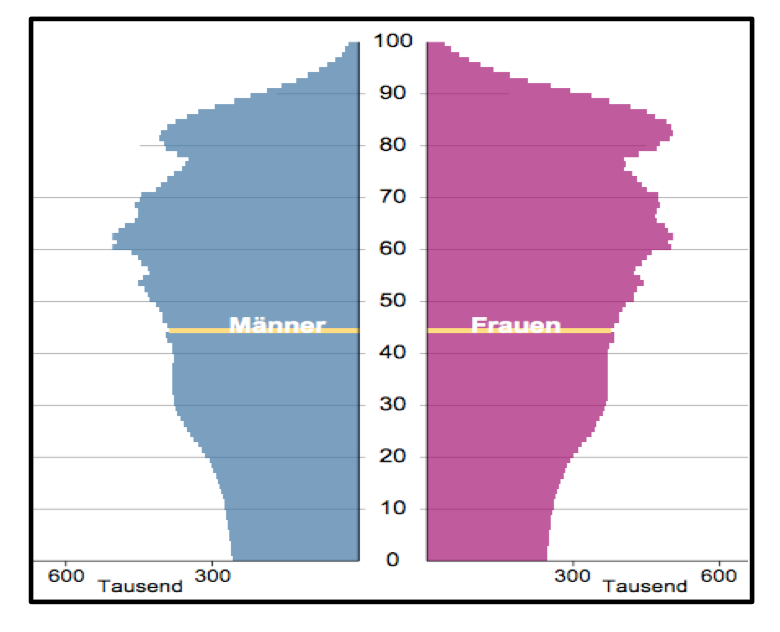
.
Die gezeigten Graphiken verdeutlichen sowohl den Modellcharakter der statistischen Graphik wie deren Fähigkeit, auch komplexe Sachverhalte "auf einen Blick" zu erschließen.
2. Modulüberblick
a) Die Datengrundlage
Bei der Aufbereitung statistischer Daten sollen die aus einer
Befragung einzelner Personen, Institutionen (Unternehmen) oder sonstiger
Merkmalsträger resultierenden Informationen systematisch zusammengestellt und
mit einfachen Methoden ausgewertet werden. Dazu betrachten wir im folgenden Kapitel die jeweiligen Merkmale separat.
In den Erhebungsunterlagen wird jede individuelle Ausprägung eines
Merkmals einzeln erfasst. Deshalb müssen in einem ersten Schritt diese Angaben
für jedes Merkmal gesammelt werden. So entsteht für jedes Merkmal eine Urliste (auch
Strichliste oder Primärtabelle genannt). Es sind in ihr noch keine
Zusammenfassungen von Objekten gleicher Merkmalsausprägungen in Gruppen oder
Klassen vorhanden.
Für die späteren Analysen wird ein Datensatz vorgestellt, der mit dem Datenanalyseprogramm SPSS
ausgewertet werden soll. Dieses wird in einem Exkurs kurz skizziert. Dabei werden einige zentrale Funktionen des Programms erläutert, die Generierung eines Datensatzes beschrieben, der Import von Excel-Dateien erklärt und erste Analyseschritte präsentiert.
b) Die tabellarische Darstellung der eindimensionalen Häufigkeitsverteilung
Mit der Weiterverarbeitung der Daten in der Datendatei wird eine leichtere Aufnahme und
Verdichtung der Information angestrebt. Dazu wird eine Ordnung und
Gruppierung dieser Daten durchgeführt. Durch die Gruppierung wird ermittelt, wie
häufig die einzelnen Merkmalsausprägungen auftreten. Deshalb wird die Anzahl der
Beobachtungen einer bestimmten Merkmalsausprägung in der Statistik als
Häufigkeit bezeichnet und die gruppierte Verteilung der Merkmale als einfache
Häufigkeitsverteilung.
Diese kann in Form einer Tabelle oder in Form
einer Graphik dargestellt werden. Beide Präsentationsformen werden im
Detail und auch für die folgenden Aufbereitungsweisen statistischer
Informationen vorgestellt.
In den meisten Fällen liegen die statistischen Daten in
absoluten Häufigkeiten (engl. frequencies) vor. Absolute Häufigkeiten werden unmittelbar als Information benutzt. Relative und prozentuale Werte
erlauben einen besseren Vergleich mehrerer Verteilungen, in denen die Anzahl der
betrachteten Objekte nicht gleich ist.
Eine weitere wichtige Form der Aufbereitung gruppierter Daten stellt die sog.
Kumulation dar. Das Auf- und Abkumulieren (auch Kumulieren und
Dissipieren) von Werten erfüllt in der Statistik mehrere Funktionen. So wird es
z.B. genutzt, um Teilmengen von Beobachtungen zu beschreiben. Mit einer
Zusammenfassung von Merkmalsausprägungen "bis unter ..." und "mehr als ..."
können z.B. Aussagen über die Häufigkeit der Familien mit weniger als drei
Kindern oder einem Einkommen von mehr als 4800 DM gemacht werden.
Im Arbeitsschritt "Beispiele und Aufgaben" des Moduls werden dazu die Möglichkeiten vorgestellt, tabellarische Auswertungen von Datensätzen mit SPSS durchzuführen.
c) Die graphische Darstellung der eindimensionalen Häufigkeitsverteilung
Unmittelbar anschaulich können
diese Häufigkeitsverteilungen auch grafisch dargestellt werden. Dazu stehen mehrere graphische Formen, wie Kreis-, Stab- und Liniendiagramme zur Verfügung. Die optimale Darstellungsform hängt dabei insbesondere vom Skalenniveau ab.
Die graphische Darstellung auf- bzw. abkumulierte Daten erfolgt über die Treppenfunktion und das Summenpolygon.
Im Arbeitsschritt "Beispiele und Aufgaben" des Moduls werden dazu die Möglichkeiten vorgestellt, graphische Darstellung eindimensionaler Häufigkeitsverteilungen mit SPSS zu erzeugen.
d) Die tabellarische Darstellung der klassierter Häufigkeitsverteilung
Da gruppierte Daten meist zu unübersichtlich sind, werden sie in der Regel
weiter zusammengefasst. Dies führt zur sog. klassierten
Häufigkeitsverteilung. Dazu sind für die einzelnen Merkmalsausprägung
Klassen zu bilden. Die relevanten Informationen bestehen aus der
Klassenuntergrenze, der Klassenobergrenze, der Klassenbreie und der Häufigkeit, der in dieser
Klasse befindlichen Beobachtungen.
e) Die graphische Darstellung der klassierten Häufigkeitsverteilung
Bei Klassierungen mit ungleichen Klassenbreiten ist nicht mehr ausschließlich
die absolute Häufigkeit interessant, sondern ebenso die sog.
Häufigkeitsdichte. Diese findet vor allem Eingang in die graphische
Präsentation klassierter Daten im Histogramm.
f) Die eigenständige statistische Analyse mit SPSS
In diesem Modul sollen die Möglichkeiten eigenständiger statistischer Analysen mit den SPSS-Beispielsdaten aus dem Mikrozensus oder mit unter Verwendung des Fragebogengenerators selbst erhobenen Daten vorgestellte werden.
3. Modulwahl
Wählen Sie ein Modul:
- II-1 Die Datengrundlage
- II-2 Die tabellarische Darstellung eindimensionaler Häufigkeitsverteilungen
- II-3 Die graphische Darstellung eindimensionaler Häufigkeitsverteilungen
- II-4 Die tabellarische Darstellung klassierter Daten
- II-5 Die graphische Darstellung klassierter Daten
- II-6 Eigene Analysen mit Mikrozensus-Daten